







基于高光谱分选设备的关键技术——分类算法
发布时间:2023-10-10
浏览次数:1747
分类算法是高光谱分选设备的关键技术之一。高光谱数据的分类算法可以分为基于光谱相似度匹配的分类方法和基于机器学习的分类方法2类。本文根据现有技术和研究资料,进行了简单总结。
分类算法是高光谱分选设备的关键技术之一。高光谱数据的分类算法可以分为基于光谱相似度匹配的分类方法和基于机器学习的分类方法2类。本文根据现有技术和研究资料,进行了简单总结。

高光谱相机原理
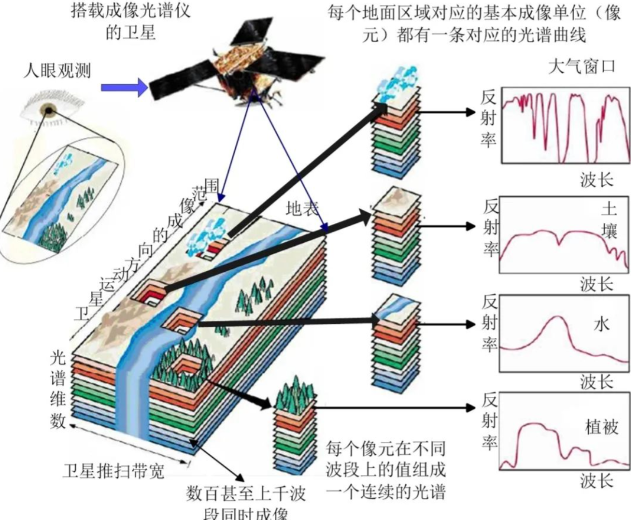
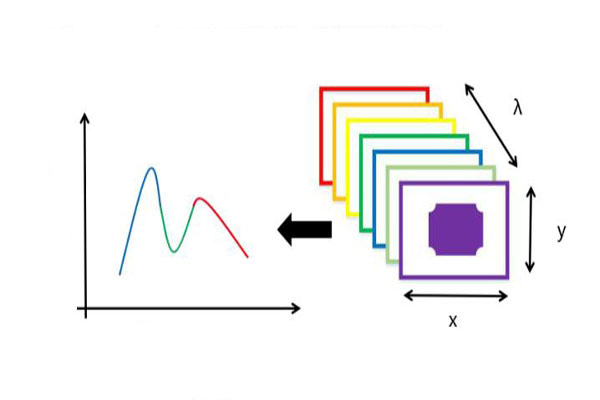
高光谱相机采集物体的反射光谱,典型的高光谱相机的原理是,光源投射到待测物体上,反射后经过相机镜头前端的狭缝进人高光谱相机内部的核心元件一—分光仪。分光仪将每一束光分成多束单色光,投到面阵相机上。面阵相机狭缝的长度方向w为像素维度,与狭缝垂直方向h为光谱维度,面阵相机w和h2个方向的分辨率决定着高光谱数据的像素分辨率和光谱分辨率。该高光谱相机的使用和线阵相机类似,一行一行的扫描,每一行的数据都是面阵相机的数据,代表的是w方向上每个像素点上的h个光谱数据,根据光谱信息进行光谱分析可以确定其化学组成,以此来鉴别物体的材质。
高光谱相机数据获取
根据高光谱相机原理可知,高光谱相机每一帧数据都是面阵相机的二维数据,而高光谱数据是三维的数据,需要对相机采集到的数据进行相应的处理后才能获得。高光谱相机数据获取分为面阵相机数据获取和数据拼接2个部分。面阵相机数据的获取与普通2D相机数据的获取过程并无差异,即先调整图像质量,然后获取图像。调整图像质量时,需要调节光源的亮度、相机光圈、焦距大小以及曝光时间等,以获得最优的图像效果。获取图像一般是连续获取数据,可以按时间间隔触发,也可以由外部I0信号触发。如果这个10信号是编码器,就可以实现按照距离触发。触发间隔有严格的要求,以保证拼接后的图像与实际物体比例一致。
面阵相机数据的获取完成后,还需要对数据进行拼接,从而得到高光谱数据。高光谱数据的格式有3种,分别为BSQ,BIL和BIP。BSQ(Band Sequential Format)格式是按波段保存,1个波段保存后接着保存第2个波段。这种格式适合对单个光谱波段中任何部分的空间(X,Y)存取。BIL(Band interleaved by line format)格式是按行保存,保存第1个波段的第1行后,接着保存第2个波段的第1行,这种格式提供了空间和光谱处理之间的一种折衷方式。BIP(Band interleaved by pixel format)格式是按像元保存,先保存第1个波段的第1个像元,然后保存第2波段的第1个像元。该格式为图像数据光谱(Z)的存取提供了最佳性能。高光谱数据拼接完成后,通常还需要1个描述文件,然后可以导入光谱分析软件进行数据处理了。
基于光谱相似度匹配的分类方法
光谱相似度的匹配算法是通过计算测试光谱向量与参考光谱向量之间的相似度来进行分类。光谱相似度的度量标准包括最小距离、光谱角度、光谱信息散度以及光谱相关性等,其中最小距离度量标准包括曼式距离和欧式距离等。光谱最小距离越小,相似性越大。光谱角度余弦值越大,相似性越大。光谱信息散度值越接近于0,相似性越大。光谱相关系数越大,相似性越大。
光谱相似度的匹配算法首先要建立待测物体的光谱库,然后计算测试光谱与光谱库中光谱数据的相似度,最后根据相似度数值以及相似度阀值来判断物体的类别。光谱相似度匹配算法的重点在于待测物体光谱库的建立,光谱库可以是来自标准的光谱库,也可以是根据待测物体建立的自定义光谱库。标准的光谱库对相机和光源的一致性要求较高,实际上不同的相机、不同的光源、不同的校准条件,得到的光谱曲线并不完全一致,所以标准光谱库中的数据一般只作为参考,工业应用上需要自定义光谱库。自定义光谱库时,首先采集待测物体的光谱数据,选取感兴趣区域(ROI),并对ROI中的数据进行端元提取,得到纯净像元,并将该像元的光谱数据存入光谱库。常用的端元提取方法包括内部最大体积法(N-FINDER)、纯像素索引法(PPl)、凸锥分析(CCA)、顶点成分分析法(VCA)等。
基于机器学习的分类方法
基于机器学习的分类方法分为非监督分类和监督分类。非监督分类是指在没有任何分类先验知识的情况下,仅依据数据本身的统计特征及自然点群的分布情况来划分类别的分类方法,代表性的非监督分类包括均值聚类算法(K-Means)、选代自组织数据分析算法(Iterative Self Organizing Data Analysis Technique)"。监督分类是指以先前提取的训练样本作为先验知识,以对训练样本的学习构建分类模型,并对其他数据进行分类的过程"。监督分类算法常用的包括高斯最大似然分类法、最小距离分类、K近邻、决策树以及支持向量机等。
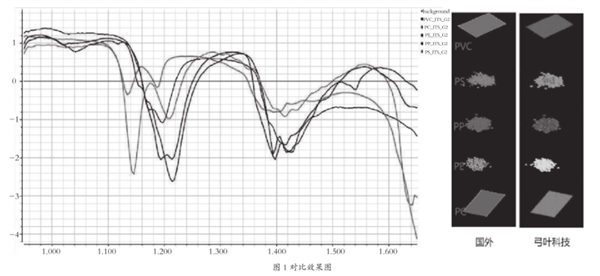
由于高光谱数据的波段数通常有200多个以上,包含丰富的信息,但有很多数据冗余,在进行监督分类之前,需要对数据进行特征提取,选取包含信息量大的波段或者特征来降低数据的冗余程度。将原始高维数据投影到一个新的低维空间,从而获得原始数据的更精简的表示,即降维,可以有效减少运算量,提高运算速度。常用的降维方法包括主成分分析(PCA)、线性判别分析(LDA)、回归系数法、连续投影法等。以PV、PS、PP、PE和PC等塑料材质的分选为例,对比效果如图1所示。
分类算法加速
由于高光谱数据包含3个维度的信息,是个数据立方体,数据量很大,因此需要对算法进行优化加速,这样才能满足工业上实时分选的需求。分类算法是基于每个像素的光谱数据进行运算的,算法加速主要是通过并行运算进行加速。
NVIDIAGPU Computing Toolkit提供了丰富的教程,可以根据CUDA提供的矩阵运算应用开发库CUBLAS_Library进行并行运算加速,也可以参考CUDACProgramming Guide,编写并行执行的核函数,直接操作GPU进行并行计算加速。相比于CPU的串行运算,GPU的并行运算能够提高5~10倍的运算速度。
并行加速的另一种平台是FPGA,FPGA器件属于专用集成电路中的一种半定制电路——可编程的逻辑列阵。基于光谱相似性匹配算法,可以通过硬件描述语言(HDL)写入FPGA,实现硬件上的并行,其运算的速度更快。FPGA的开发难度较大,并行占用的FPGA资源较多,需要大容量的FPGA。
上一页 : 高光谱,多光谱及超光谱的区别?
下一页 : 近红外光谱(NIR)应用包含哪些?

相关产品
-
高光谱数据降维和高光谱数据预测模型构建方法有哪些?
高光谱信息在采集的过程中存在光散射、检测物图像不规则以及随机噪声等不利因素,会使光谱曲线出现不平滑,信噪比较低等问题,所以在进行相关数据分析之前需要进行相应的处..
-
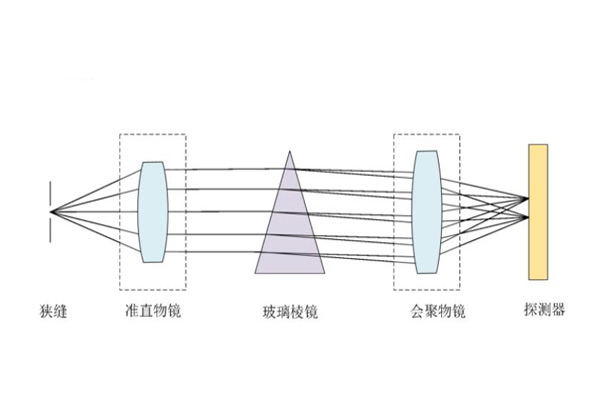
高光谱成像仪最常见的三种分光方式是哪三个?
对于高光谱成像仪而言,其分光系统是高光谱成像仪中的关键部分,直接影响着系统的分光性能、结构的复杂程度、重量和体积等。那么, 高光谱成像仪最常见的三种分光方式是哪..
-

影响无人机高光谱植被覆盖度估算精度的主要因素
近年来,无人机高光谱遥感技术凭借其高空间分辨率、高光谱分辨率、灵活机动等优势,逐渐成为植被覆盖度估算的重要手段。..
-

无人机高光谱在农作物病害监测中的应用优势
无人机高光谱遥感技术作为新兴的无损检测手段,通过搭载高光谱成像设备,能够快速获取农作物冠层的精细光谱信息,为病害的早期识别、定量分析与精准防控提供数据支撑。本文..










